Info
- 요약자: 천용희 (Yonghee Cheon)
- 논문 제목: NeuralCook – Image2Ingredients and Cooking Recommendation using Deep Learning
- 링크: https://github.com/SumithBaddam/NeuralCook/blob/master/NeuralCook.pdf
- 흥미로운 점: NLP와 비젼을 엮어 joint embedding을 만든 후 추천 로직 개발
- 세부 코멘트: 맨 아래 위치
[0] 초록
- 제안 : CV와 NLP 딥러닝 아키텍쳐를 활용한 애플리케이션
- 도메인 : 요리
- 주요 기능
- Input : 음식 이미지
- 재료정보 추출
- 레시피 제공
- Input : 재료
- 레시피 추천
- 중심 아이디어 : CV와 NLP의 SOTA 테크닉을 활용해 Joint Embedding 생성
- Input : 음식 이미지
[1] 서론
제안배경 : 많은 심리학적 긍정 요인도 있는 Foodstagramming(미적으로 잘 나온 음식 사진을 인스타그램에 업로드하는 것)은 요즘 인기 있는 인스타그램 주제다. 우리는 음식할 시간이 적은 바쁜 현대인이 사진들을 보다가 바로 레시피와 음식 재료들을 알 수 있도록 하는 딥러닝 애플리케이션을 제안한다. 또한 집에 재료들이 있는데 어떤 음식을 만들어야 하는 지 모를 때에도 재료를 우리 모델에 검색하면 추천 요리와 레시피들을 얻을 수 있다.
[2] 배경과 관련 연구 소개
- 음식 분류
- Bossard et al. : Food-101 시각분류 데이터셋 개발, baseline accuracy로 50.8% 기록
- 음식 이미지를 인풋으로 레시피 등 정보 제공
- Facebook AI Research with MIT : 이미지를 인풋으로 하여 DB에 있는 레시피를 리턴해주는 애플리케이션 pic2recipe 개발
- Amaia Salvador : Recipe1M 데이터셋 활용하여 cross-modal embedding 기법 제안
- Herranz et al. : 음식 이미지와 위치정보, 유사 음식 이미지, 레시피, 근처 음식점, 영양 정보들을 통합하는 multi-model 프레임워크 제안
- Chang Liu : 음식 종류와 제공크기 등을 파악하는 CNN 아키텍쳐 제안
- Facebook Inverse Cooking Recipe Generation : retrieval-based approach로 인풋 이미지에 대한 레시피 제공
- 본 연구의 새 데이터셋 제안 : Food-101 데이터셋에 대해 재료에 대해 보다 자세한 정보를 제공하는 데이터셋
[3]방법론
[3-1] Dataset
- Primary Sources : Food-101, allrecipes.com and Recipe1M+
- Specifications : 120,000장의 이미지, 5,000개 재료, 101개의 class
[3-2] Data 전처리
- 텍스트
- 데이터 : 웹 크롤링으로 얻은 비정형 텍스트 형태 재료 데이터
- 처리
- 재료 이름을 정확히 얻기 위해 NLP, 텍스트 분석, 전처리, 키워드 인식 작업 진행
- 유사 키워드를 하나로 인식하기 위해 OpenRefine 사용
- 이미지
- 데이터 : Food-101, allrecipes.com의 음식 이미지
- 처리 : 512 * 512의 이미지로 리사이즈 및 정제
[3-3] 모델 학습
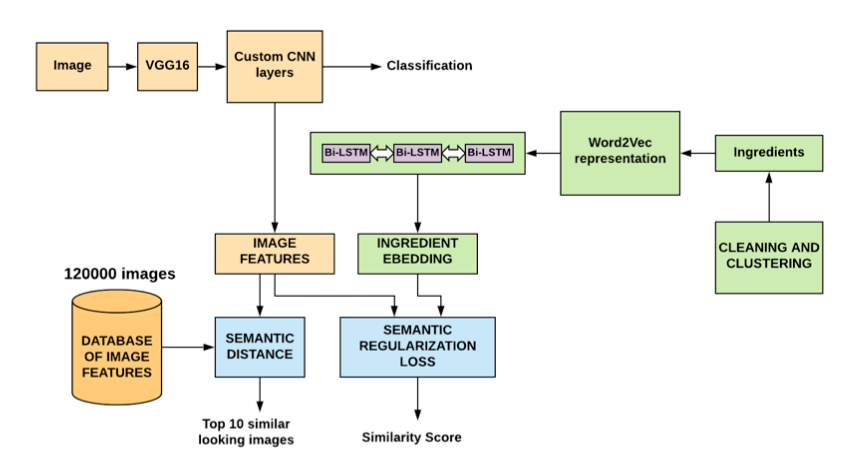
- 모델 개요
- 이미지와 텍스트로 나누어 각각 CNN과 Bi-LSTM으로 임베딩 후 이를 이용하여 결합 임베딩 생성
- A . 이미지 임베딩 : CNN
- ImageNet으로 pretrain한 VGGNet을 베이스 모델로 CNN 레이어를 추가, 101개 class 분류 학습
- 학습이 완료된 후 분류를 위한 마지막 softmax층을 제거하고 마지막 FC layer를 이미지 임베딩으로 사용 (4096차원 벡터)
- B . 텍스트 임베딩 : Word2Vec + Bi-LSTM
- 전처리한 재료정보 텍스트를 Word2Vec 통해 1차 임베딩을 얻어내고, 이를 다시 Bi-LSTM 네트워크에 태워 임베딩 공간 획득
- C . 결합 임베딩
- 음식 사진과 재료쌍의 유사도를 높게 만들어주도록 하는 결합 임베딩 생성 (cosine similarity loss)
[3-4] 웹 어플리케이션으로 테스트
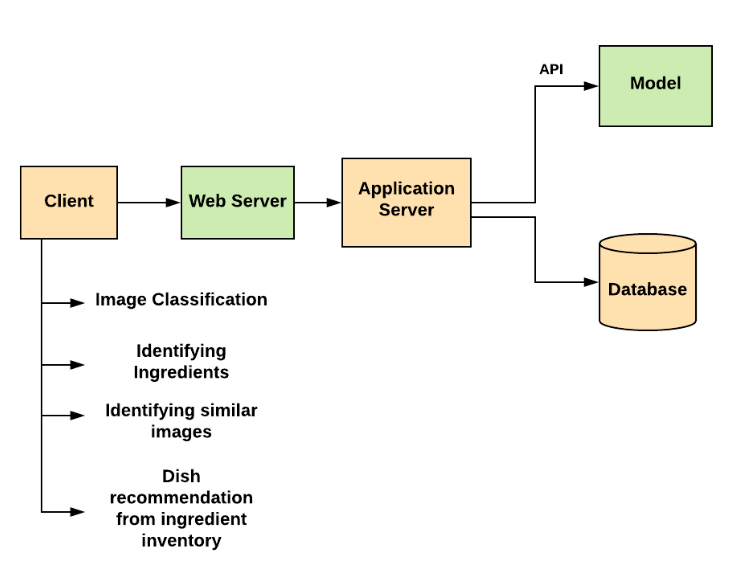
- 개발항목 : 웹 어플리케이션과 REST API 개발
- 목적 : 사용자들이 모델을 사용해보고 피드백 송신
- 기술스택
- Server : Node JS
- Model Serving : Python
- Requst Methods : HTTP GET, HTTP POST
[4] 결과
[4-1] 이미지 분류 태스크

- Metric : Accuracy
- Score : 85%
- Number of Test Inputs : 10,000
[4-2] 재료 추출 태스크
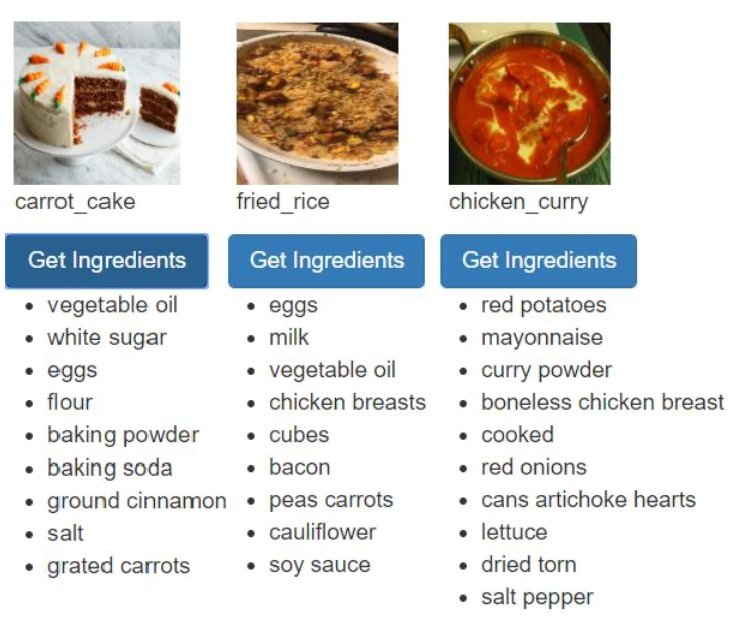
- 특징 : 이미지 분류 모델은 단순히 fried rice로 분류한 사진을, Bi-LSTM 재료 모델은 그 안의 chicken breast 채료를 찾아내어서 분류 모델과 재료추출 모델이 서로 보완할 수 있음을 도출
[4-3] 음식 유사 이미지 제공
- Metric : Accuracy
- Score
- Top-5 : 91%
- Top-10 : 95%
- Database : 120,000 Images
[4-4] 재료로부터 요리 추천
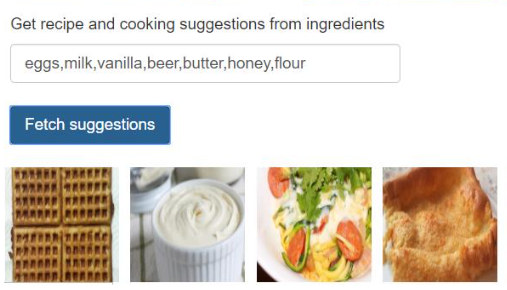
[5] 토의
- 평가 : 나쁘지 않은 accuracy지만, 한계 존재
- 예상 원인
- 분류모델의 class가 101개로 제한
- 부족한 인풋 이미지 퀄리티
- 이미지 perspective 문제
- 한 사진에 여러 이미지 출현 문제
- 학습 데이터의 anomaly와 전처리시 오류
[6] 결론
- 웹 어플리케이션으로 오픈소스 형태 공개한 데 의의
- 카테고리를 늘려서 모델 개선하는 작업을 진행할 예정
코멘트
- Pros
- 이미지와 텍스트의 join embedding 사용 아이디어가 좋았음
- 분류문제를 풀 때 사전학습된 모델을 파인튜닝하는 전형적인 방식이 real world problem에도 잘 들어맞는다는 것을 보여줌
- Cons
- [내용적] 텍스트 임베딩 상 Bi-LSTM의 사용 이유와 성능을 추가적으로 표현해줬으면 좋았을 것. 우선 unordered set 전체를 임베딩하기 위한 알고리즘으로 판단
- [내용적] 재료 -> 음식 추천은 주요 로직과 평가 모두 페이퍼에서 논하지 않아 아쉬움
- [내용적] 재료 -> 음식 추천은 페이퍼에서 나온 것으로 볼 때 추천 로직보다는 단순 검색로직에 가까워 보임
- [형식적] 영어 문법 오류와 문맥에 어울리지 않는 문장이 다수 있어내용 판단시 애로사항 존재
- [형식적] 서론에서 전체 맥락과 먼 내용들 아쉬움
- 아이디어 제안
- 같은 문제를 이미지 내 재료들을 object detection한 후 detect된 재료들의 텍스트 임베딩을 활용하여 음식을 추천하는 로직 실험
- 재료 -> 레시피 추천 로직에서, 여러 레시피들 중 쿼리로 들어온 재료가 중요하게 여겨지는 레시피를 추천하는 것이 좋은 추천이라는 전제에서 (해당 재료가 주재료인 레시피 위주) 재료의 사용량이나 레시피에서 재료의 등장빈도 등을 따로 로직으로 사용
- Image – Ingredient 임베딩시
- Attention 활용하여 주요 재료 파악하는 네트워크
- triplet loss 활용하여 유사도 임베딩